پیک نوروزی ۱۴۰۱ - روزهای ۵ تا ۸
در طی نوروز ۱۴۰۱، در ۸ توویت با هشتگ #پیکنوروزی ۸ سوال و تمرین مطرح کردم. در این بلاگپست و بخش قبل این سوالها و پاسخها را آوردهام.
در این بخش:
- روز ۵. پیادهسازی اپراتور LIKE
- روز ۶. جایزههای اسمولیان
- روز ۷. چاپ همهی درختهای دودویی
- روز ۸. اختلاف سرعت sum1 و sum2
روز ۵. پیادهسازی اپراتور LIKE
لینک توویت: https://twitter.com/pykello_fa/status/1507248675491237893
اپراتور like در sql برای چک کردن فرمت یه رشته استفاده میشه. مثلا در شکل زیر سطر ۱ چک میکنه که آیا s با ab شروع میشه، و سطر ۲ چک میکنه که آیا یه جایی تو s زیررشتهی xyz وجود داره.
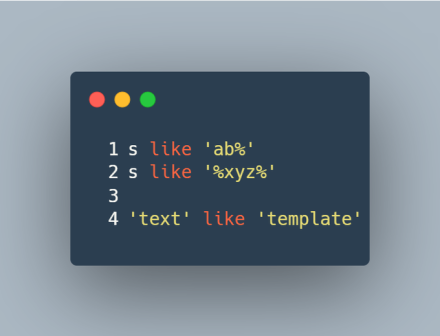
در زبان دلخواهتون تابعی بنویسین که یه رشته به شکل سطر ۴ بگیره و اگه text مطابق رشتهی template بود، True برگردونه وگرنه False. قوانین تطبیق:
- ٪: صفر یا بیشتر کاراکتر
- خط زیر(underscore): دقیقا یک کاراکتر
- در داخل رشتهها به جای
'از دو تا'استفاده میکنیم (مثل مثال یکی مونده به آخر).
دقت کنید که ورودی تابع یه رشتهی سرهمه، نه دو تا رشته. خودتون باید parse کنین.
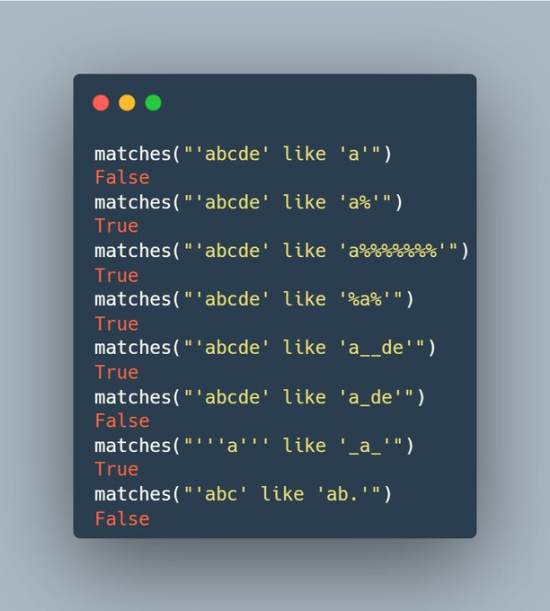
اگه دلتون خواست از regex استفاده کنین، اگه هم راحت بودین از اول تا تهش رو خودتون پیادهسازی کنین، یا اصلا از هر کتابخونهای دلتون خواست استفاده کنین.
اگه این براتون آسون بود و خواستین نسخهی کمی پیچیدهترش رو حل کنین، اینو حل کنین: Timus #1177
دقت کنید که اینو تو هر زبونی دلتون خواست میتونین بنویسین، مثلا پایتون، … ربطش به sql فقط صورت مسالهاست، لزومی نداره از sql استفاده کنین. اصلا برای جالبتر شدن بهتره از sql استفاده نکنین.
پاسخ
راهحل من برای سوال کاملتر (Timus #1177) با استفاده از زبان هسکل: https://gist.github.com/pykello/536dcde060db18c892d5
روز ۶. جایزههای اسمولیان
لینک توویت: https://twitter.com/pykello_fa/status/1507606717583933441
-
سه تا جایزهی الف و ب و ج داریم. شما قراره یه جمله بگین، اگه این جمله صحیح بود، یکی از جوایز الف یا ب رو میگیرین، وگرنه جایزهی ج. شما میخواین حتما جایزهی الف رو ببرین. چه جملهای میتونین بگین که حتما جایزهی الف رو ببرین؟
-
چهار جایزهی الف و ب و ج و د داریم. این دفعه اگه جملهای که میگین صحیح بود، الف یا ب رو میگیرین، اگه غلط بود ج یا د. شما میخواین حتما جایزهی ج رو ببرین. چه جملهای میتونین بگین که حتما این جایزه رو ببرین؟
پاسخ و بحث
لینک توویت پاسخ: https://twitter.com/pykello_fa/status/1507856501137981449
توضیح علیبیگی برای بخش اول سوال:
عکس راه حل برای مساله اول #پیکنوروزی pic.twitter.com/TxfVWZ3yy0
— Ali Baygi (@alibaygi) March 26, 2022
پاسخ بخش دوم سوال هم به طور مشابه میشود: «من جایزهی د رو میبرم»
این سوال جزو مسالههای اول کتاب «to mock a mockingbird» ریموند اسمولیان بود. اگه به اینطور مسالهها علاقه دارین، بقیه کتاب رو بخونید.

روز ۷. چاپ همهی درختهای دودویی
لینک توویت: https://twitter.com/pykello_fa/status/1507968157901803520
در زبان دلخواهتون تابعی بنویسید که تمام درختهای دودویی (درجهی هر گره ۱ یا ۲) با n گره رو تولید و با استفاده از o - | + چاپ کنه.

اگه حوصلهی این سوال رو ندارین، یه سوال مشابه کمی آسونتر ولی از همین جنس:
تابعی بنویسید که پرانتزبندیهای مجاز با n پرانتز رو به دست بیاره:
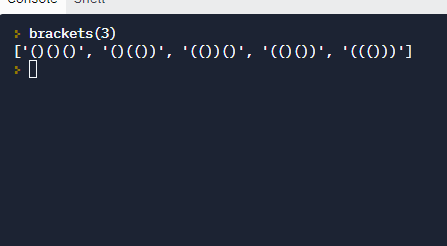
پاسخ
لینک توویت پاسخ: https://twitter.com/pykello_fa/status/1508291797742616576
- کد من برای این مساله: BinaryTrees/main.py
- کد تمیزتر @behdadesfahbod برای این مساله: behdad/print_trees.py
- کد من برای مسالهی پرانتزها: parentheses/main.py
روز ۸. اختلاف سرعت sum1 و sum2
لینک توویت: https://twitter.com/pykello_fa/status/1508321695802617859
تابع sum1 و sum2 هر دو از لحاظ منطقی یک کار انجام میدهند، تمام اعضای آرایهی دوبعدی data را جمع میکنند. با این تفاوت که sum1 سطر به سطر حرکت میکند و sum2 ستون به ستون.
چرا تابع sum1 حدود ۱۹ برابر سریعتر از تابع sum2 است؟
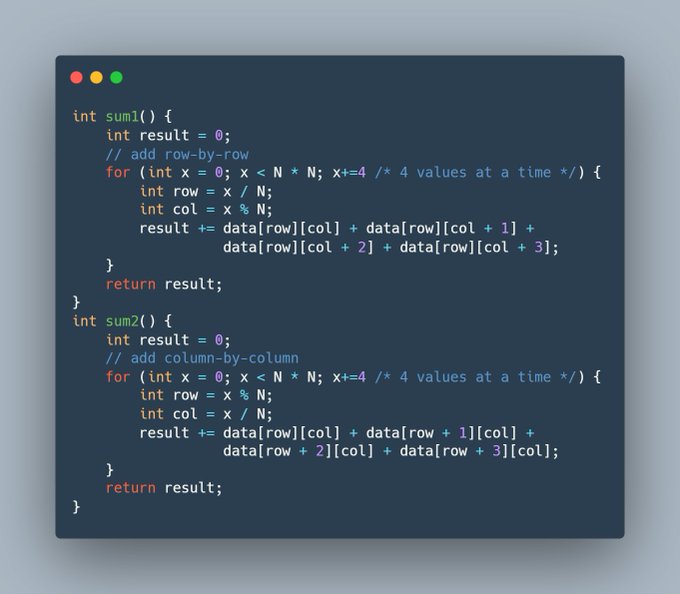
کامپایل و مقایسهی سرعت در تصویر زیر (اگه تست کردید، شما هم از clang و فلگ O3 استفاده کنید).
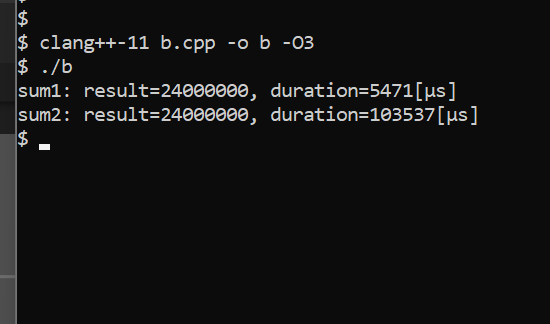
کد کامل در: https://gist.github.com/pykello/c453e0ba413932ccb7d09aa327b75aca
توضیح: از دو حلقهی تو در تو استفاده نکردم، چون کامپایلر اتوماتیک بهینهسازی میکرد و ترتیب حلقهها را اتوماتیک جابجا میکرد و سرعت هر دو حالت یکی میشد.
پاسخ و بحث
لینک توویت پاسخ: https://twitter.com/pykello_fa/status/1508645489637421064
دلایل اصلی همانطور که خیلیها اشاره کردند:
- استفادهی بهینهتر از کش سیپییو
- استفاده از دستورالعملهای SIMD
cpu چندین لایه کش دارد، که اندازه و تاخیر دسترسی (بر حسب کلاک) به لایههای مختلف cpu من را میبینید.
همانطور که میبینید، دسترسی به L1 ده برابر سریعتر از L3 است که آن نیز چند برابر سریعتر از دسترسی مستقیم به RAM است.

نکتهای که وجود دارد این است که واحد کش شدن ۶۴ بایت است، و شما اگر یک خانهی ۴ بایتی هم بخوانید، مثل data[0][0]، پانزده خانهی بعدی نیز کش خواهند شد و ۱۵ عمل بعدی همه از کش خواهند خواند.
وقتی دادهها را سطربهسطر پردازش میکنیم، به احتمال زیاد هر ۱۶ عدد یک بار نیاز داریم بالاتر از L1 دسترسی پیدا کنیم، ولی در پردازش ستونبهستون، با توجه به سایز محدود L1 (۳۲ کیلوبایت)، کلی از مقادیر کش شده بدون استفاده دور ریخته میشوند.
در تصویر تعداد دسترسیها به L3 (=LLC) را در هر ۲ تابع میبینید.
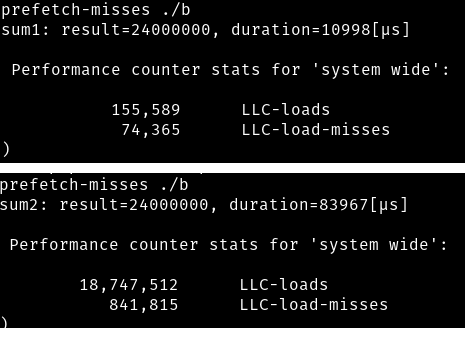
همانطور که میبینید، در sum1 تعداد دسترسیها به L3 بسیار کم است، چون اکثر مقدارها در L1 و L2 پاسخ داده شدهاند. ولی در sum2 اکثر مقادیر از L1 و L2 یافت نشدند و به L3 رسیدند که بعضی از آنها نیز از RAM خوانده شده.
نکتهی ۲ این است که به علت پشت سر هم بودن مقادیر جمع شده در حافظه در sum1، کامپایلر از دستورالعملهایی استفاده میکند که در یک حرکت چندین عدد را با هم جمع میکنند. برای آشنایی با این دستورالعملها به لینک زیر مراجعه کنید: Single_instruction,_multiple_data