بهینهساز پستگرس، بخش یکم
در این نوشته و بخشهای بعدی به مباحث زیر میپردازیم:
- روشهای یافتن سطرها در پستگرس
- روشهای انجام join در پستگرس
- چند مثال از join که کند است و چگونه سریعتر کنیم.
در این بخش، تنها به مورد ۱، یعنی روشهای یافتن سطرها میپردازیم.
لینک ویدئو: youtu.be/SoJp8cznKrE
برای سادهسازی، پردازش موازی پستگرس در مثال خاموش کردهایم.
postgres=# set max_parallel_workers to 0;
postgres=# set max_parallel_workers_per_gather to 0;اصل قضیه مباحث بحث شده حتی موقعی که پردازش موازی روشن باشد هم صادق است.
مروری کوتاه بر معماری پستگرس
فرض کنید پایگاه داده شما دارای دو جدول به نامهای users_table و orders_table است و دارای یک ایندکس به نام user_id_idx.

برای جزییات اجرای کوئری، به پست پستگرس چگونه کار میکند؟ جلسه یک - زندگی یک کوئری مراجعه کنید.
جنبههایی از معماری پستگرس در نمودار بالا که در این مقاله برای ما مهم است:
- هر کدام از جدول ها و ایندکسها در فایل یا فایلهایی در فایل سیستم ذخیره میشوند. مثلا در مثال بالا جدول users_table در فایل
base/12662/16455ذخیره شده است و ایندکسuser_id_indexدر فایلbase/12662/16512ذخیره شده است. - پستگرس هر فایل را به صفحههای ۸ کیلوبایتی تقسیم میکند. این صفحهها واحد خواندن از فایل هستند. یعنی حتی اگر پستگرس تنها به ۴ بایت هم نیاز داشته باشد، تمام صفحه ۸ کیلوبایتی شامل آن ۴ بایت را میخواند.
- پستگرس برخی از این صفحههای ۸ کیلوبایتی را در بخش Shared Buffers کش میکند. در تصویر بالا سه صفحه از جدول users_table، دو صفحه از orders_table، و یک صفحه از ایندکس user_id_index کش شده است. این کش برای این است که پستگرس کمتر به فایل مراجعه کند و در نتیجه دسترسی کمتری به دیسک داشته باشد، زیرا دسترسی به دیسک کند است. اندازه این کش را میتوان توسط پارامتر shared_buffers تغییر داد، و مقدار پیشفرض آن ۱۲۸ مگابایت است.
ساختار یک صفحه یک جدول
هر صفحه جدول شامل اطلاعات یک سری سطر است. شکل زیر ساختار یکی از این صفحههای ۸ کیلوبایتی را نمایش میدهد:
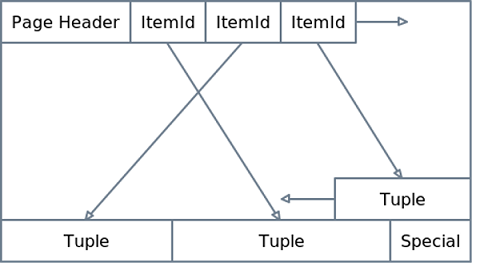
در شکل بالا این صفحه دارای اطلاعات سه سطر است. در ابتدای صفحه، سربرگ (Header) صفحه است. سپس اشارهگرها به اطلاعات هر کدام از سطرها. اطلاعات سطرها به ترتیب عکس از آخر صفحه چیده میشوند.
شمارهگذاری سطرها. پستگرس برای اینکه بتواند از ایندکس به سطرهای یک صفحه اشاره کند، آنها را شمارهگذاری میکند. پستگرس سطرهای یک جدول را با یک جفت عدد شمارهگذاری میکند که عدد اول شماره صفحه و عدد دوم شماره سطر در آن صفحه را مشخص میکند. مثلا اگر در مثال بالا شماره صفحه 4 باشد، سه سطر موجود در این صفحه (4, 1) و (4, 2) و (4, 3) شماره گذاری میشوند و (5, 10) اشاره میکند به سطر دهم در صفحه پنجم جدول.
ساختار یک ایندکس btree
در شکل زیر ساختار یک ایندکس btree را میبینید.
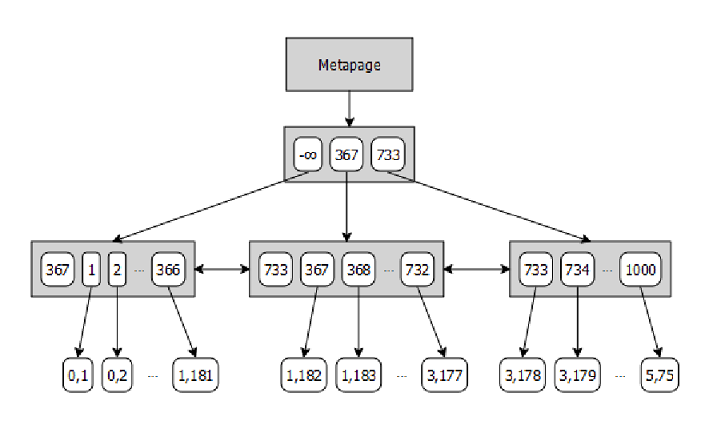
- هر کدام از گرههایی که با رنگ تیره مشخص شدهاند به صورت یک صفحهی هشت کیلوبایتی در دیسک ذخیره میشوند.
- گرههای میانی یا به گرههای میانی پایینتر یا به گرههای برگ اشاره میکنند.
- گرههای برگ شامل یکسری اشارهگر به سطرهای جدول هستند. همانطور که مشاهده میکنید، این اشارهگر جفت عدد هستند که مفهوم این جفتها در بخش پیش توضیح داده شد.
مثلا فرض کنید میخواهیم x = 368 را در ایندکس بالا بیابیم. ۳۶۸ بین ۳۶۷ و ۷۳۳ قرار دارد، پس اشارهگر مربوط به ۳۶۷ را دنبال میکنیم و به دومین گره برگ میرسیم. در این گره در این گره ۳۶۸ را پیدا میکنیم و میفهمیم که این مقدار ۱۸۳ امین سطر در صفحه اول جدول است.
در این مثال تنها یک سطح میانی بود. تعداد سطوح میانی میتوان بیشتر باشد. برای جزییات بیشتر به این مقاله مراجعه کنید.
یافتن سطرها
فرض کنید جدولی را به صورت زیر ایجاد کردیم:
CREATE TABLE demo2 (x numeric, y int);و تعدادی سطر با مقادیر تصادفی به آن اضافه کردیم:
INSERT INTO demo2
SELECT random() * 10000, i
FROM generate_series(1, 1000) i;اکنون پستگرس کوئرهایی با شکل SELECT * FROM demo2 WHERE x = 1234 را چگونه میتوان پاسخ دهد؟ در این مرحله چون هیچ دادهساختاری برای یافتن سریعتر دادههای این جدول نساخته نشده، پستگرس برای این کوئری و هر کوئری دیگری که به دادههای جدول demo2 نیاز دارد، همه جدول را پیمایش میکند. یعنی تک تک ۱۰ میلیون سطر را.
این قضیه را میتوانیم با فرمان EXPLAIN بررسی کنیم:
postgres=# EXPLAIN SELECT * FROM demo2 WHERE x = 1234;
QUERY PLAN
-----------------------------------------------------------
Seq Scan on demo2 (cost=0.00..179081.71 rows=1 width=15)
Filter: (x = '1234'::numeric)
(2 rows)عبارت Seq Scan در خروجی بالا نشان میدهد که کل جدول پیمایش میشود.
اکنون یک ایندکس بر روی ستون x ایجاد میکنیم:
CREATE INDEX idx_x ON demo2(x);
ANALYZE demo2;(با اجرای دستور ANALYZE پستگرس آماری برای جدول جمعآوری کند. در بخشهای بعد توضیح بیشتری در این مورد خواهیم داد)
اکنون اگر کوئری بالا را تکرار کنیم، مشاهده میکنیم که پستگرس از ایندکس ساخته شده استفاده میکند:
postgres=# EXPLAIN SELECT * FROM demo2 WHERE x = 1234;
QUERY PLAN
--------------------------------------------------------------------
Index Scan using idx_x on demo2 (cost=0.43..8.45 rows=1 width=15)
Index Cond: (x = '1234'::numeric)
(2 rows)Index Scan چه میکند؟
عمل Index Scan اشارهگر سطرها را از ایندکس پیدا میکند و سپس آن اشارهگرها را دنبال میکند و مقدار سطرها را از جدول اصلی میخواند.
یک ایندکس تنها مقدار ستونهایی که ایندکس بر روی آنها ساخته شده را دارد. مثلا در مثال بالا که idx_x بر روی ستون x ساخته شده است، ایندکس تنها مقدار x را دارد و مقدار ستون y را ندارد.
در کوئری بالا، یعنی SELECT * FROM demo2 WHERE x = 1234 مقدار همه ستونها درخواست شده است، پس اطلاعات موجود در ایندکس برای پاسخ به این کوئری کافی نیست. بنابراین پس از یافتن اشارهگرها از ایندکس، مقدار خود سطر از خود جدول خوانده میشود.
Index Only Scan
اکنون در کوئری بالا یک تغییر کوچک میدهیم و به جای مقدار همه ستونها، تنها مقدار ستون x را درخواست میکنیم:
postgres=# EXPLAIN SELECT x FROM demo2 WHERE x = 1234;
QUERY PLAN
-------------------------------------------------------------------------
Index Only Scan using idx_x on demo2 (cost=0.43..8.45 rows=1 width=11)
Index Cond: (x = '1234'::numeric)
(2 rows)دقت کنید که اکنون کوئری از Index Only Scan استفاده میکند.
چرا؟ چون همه اطلاعات مورد نیاز این کوئری از ایندکس یافته میشود و نیازی به مراجعه به خود جدول نیست.
مزیت Index Only Scan به Index Scan چیست؟
اندازه فایل جدول و فایل ایندکس را با دستورهای زیر به دست میآوریم:
postgres=# SELECT pg_size_pretty(pg_relation_size('demo2'));
pg_size_pretty
----------------
423 MB
(1 row)
postgres=# SELECT pg_size_pretty(pg_relation_size('idx_x'));
pg_size_pretty
----------------
301 MB
(1 row)همانطور که میبینید در این مثال انداز جدول حدود ۱.۴ برابر اندازه ایندکس است. پس اگر هم به ایندکس و هم به جدول رجوع کنیم، حدود ۲.۴ برابر داده بیشتری نسبت به حالتی که تنها به ایندکس رجوع کنیم خواهیم خواند. خواندن از دیسک کند است. بنابراین پستگرس و سیستم عامل هر کدام بخشی از دادههای فایل را کش میکنند تا تعداد دسترسیها به دیسک کمتر شود. وقتی حجم دادهای که میخوانیم کمتر باشد، احتمال اینکه دادهها در حافظه اصلی کش شده باشند بیشتر است و تعداد دسترسیها به دیسک کمتر میشود و بنابراین کوئری سریعتر اجرا میشود.
Bitmap Index Scan
فرض کنید شرط کوئری را به x < 423 تغییر دهیم. این شرط برای حدود ۴ درصد از سطرهای جدول صادق است.
اکنون مشاهده میکنیم که پستگرس به جای استفاده از Index Scan، از الگوریتمی به نام Bitmap Index Scan استفاده میکند:
postgres=# EXPLAIN SELECT avg(y) FROM demo2 WHERE x < 423;
QUERY PLAN
-----------------------------------------------------------------------------------
Aggregate (cost=71942.26..71942.27 rows=1 width=32)
-> Bitmap Heap Scan on demo2 (cost=11541.94..70888.87 rows=421355 width=4)
Recheck Cond: (x < '423'::numeric)
-> Bitmap Index Scan on idx_x (cost=0.00..11436.60 rows=421355 width=0)
Index Cond: (x < '423'::numeric)
(5 rows)در خروجی بالا، پستگرس در مرحله Bitmap Index Scan با استفاده از ایندکس idx_x، لیست تمام صفحههای ۸ کیلوبایتی که دارای سطرهای مورد نیاز ما هستند را میابد، و سپس در مرحله Bitmap Heap Scan تمام سطرهای این صفحههای انتخاب شده را میخواند. چون سطرهای مورد نیاز ما زیرمجموعهی سطرهای این صفحههاست، پستگرس شرط x < 423 را برای هر کدام از سطرهای خوانده شده دوباره بررسی میکند.
لیست صفحههای انتخاب شده در مرحله Bitmap Index Scan به صورت یک بیتمپ یا دنبالهای از صفر و یک است، که صفحههای انتخاب شده با یک و بقیه صفحهها با صفر مشخص میشوند. مثلا اگر ۵ صفحه داشته باشیم و خروجی این مرحله 00110 باشد، یعنی فقط صفحههای سوم و چهارم انتخاب شدهاند.
آیا پستگرس همیشه از ایندکس استفاده میکند؟
فرض کنید شرط کوئری را به x < 4235 تغییر دهیم. این شرط برای حدود ۴۰ درصد از سطرهای جدول صادق است.
به صورت تئوری پستگرس میتواند از ایندکس idx_x برای یافتن سطرهایی که در این شرط صدق میکنند استفاده کند. ولی میبینیم که پستگرس به جای استفاده از این ایندکس ترجیح میدهد کل جدول را پیمایش کند:
postgres=# explain SELECT avg(y) FROM demo2 WHERE x < 4235;
QUERY PLAN
----------------------------------------------------------------------
Aggregate (cost=189651.11..189651.12 rows=1 width=4)
-> Seq Scan on demo2 (cost=0.00..179077.56 rows=4229421 width=4)
Filter: (x < '4235'::numeric)
(3 rows)چرا؟ چون پستگرس تشخیص داده است که برای پیمایش ۴۰ درصد از سطرها، هزینه استفاده از ایندکس بیش از پیمایش تک تک سطرها خواهد بود.
برای اینکه ببینیم آیا تصمیم پستگرس معقول است، کوئری را یکبار با الگوریتم انتخاب شده توسط پستگرس اجرا میکنیم، و سپس پستگرس را مجبور میکنیم که از ایندکس استفاده کند و زمان هر دو حالت را مقایسه میکنیم:
postgres=# SELECT avg(y) FROM demo2 WHERE x < 4235;
avg
----------------------
5001717.501182855257
(1 row)
Time: 1388.657 ms (00:01.389)
postgres=# EXPLAIN SELECT avg(y) FROM demo2 WHERE x < 4235;
QUERY PLAN
------------------------------------------------------------------------------------
Aggregate (cost=383939.81..383939.82 rows=1 width=32)
-> Index Scan using idx_x on demo2 (cost=0.43..373366.26 rows=4229421 width=4)
Index Cond: (x < '4235'::numeric)
(3 rows)
postgres=# SELECT avg(y) FROM demo2 WHERE x < 4235;
avg
----------------------
5001717.501182855257
(1 row)
Time: 8347.422 ms (00:08.347)همانطور که مشاهده میکنید، تصمیم پستگرس برای عدم استفاده از ایندکس بسیار خوب بود و در این مورد حدود ۶ برابر سریعتر از استفاده از ایندکس است.
تخمین هزینه پستگرس
در مثال بخش پیش پستگرس چگونه تشخیص داد که استفاده از ایندکس بدتر از عدم استفاده از آن است؟
برای اینکار پستگرس هزینه هر کدام از روشها را محاسبه میکند و الگوریتم با کمترین هزینه را محاسبه میکند.
به عنوان نمونه، در مثال بالا هزینه کوئری با پیمایش کامل 189651.12 محاسبه شد و هزینه با استفاده از ایندکس 383939.82 محاسبه شد. چون هزینه پیمایش کامل کمتر از استفاده از ایندکس حساب شد، الگوریتم پیمایش کامل انتخاب شد.
تخمین تعداد سطرها. گام اول برای تخمین هزینه، این است که تخمین زده شود چند سطر از جدول برای پاسخ به کوئری نیاز هستند. برای این کار، پستگرس آمار خلاصهای از ستونهای جدول نگهداری میکند. مثلا برای مشاهده آمار نگهداری شده برای ستون x از جدول demo2 از دستور زیر استفاده میکنیم.
postgres=# select * from pg_stats where tablename = 'demo2' and attname='x';
-[ RECORD 1 ]----------+------------------------------------------------------------------------
schemaname | public
tablename | demo2
attname | x
inherited | f
null_frac | 0
avg_width | 11
n_distinct | -1
most_common_vals |
most_common_freqs |
histogram_bounds | {0.71681,95.25875,195.28383,295.39330,401.72351,...,9794.28152,9888.19313,9999.76112}
correlation | 0.0023217532
most_common_elems |
most_common_elem_freqs |
elem_count_histogram |(برای سادگی مقادیر ستون histogram_bounds را خلاصه کردهام)
ستون histogram_bounds بازههایی از مقادیر ستون x را نگه میدارد که تعداد سطرهای دارای مقدار در این بازهها تقریبا برابر است.
یعنی تعداد سطرهایی که مقدار x آنها بین 0.71681 و 95.25875 برابر با تعداد سطرهایی است که مقدار x آنها بین 95.25875 و 195.28383 است، و همچنین برابر با تعداد سطرهایی است که مقدار x آن بین 195.28383 و 295.39330 است.
با استفاده از این ستون، وقتی یک کوئری با شرط x < 4235 دریافت میشود، میتوان تخمین زد که چند درصد از سطرهای جدول با این شرط سازگار هستند.
همچنین تخمین تعداد کل سطرهای جدول demo2 را میتوان از جدول سیستمی pg_class درآورد:
postgres=# select reltuples from pg_class where relname='demo2';
-[ RECORD 1 ]-----------
reltuples | 9.999805e+06پستگرس با ضرب تخمین تعداد کل سطرها با تخمین درصد سطرهای برقرار کننده شرط x < 4235، تعداد سطرهای برقرار کنندهی این شرط را تخمین میزند. در مثال بالا، این تخمین برابر است با 4229421.
تخمین هزینه به ازای هر سطر. حال پستگرس مدلی داخلی دارد که حدس میزند هر الگوریتمی به ازای هر سطر چه تعداد از چه عملهایی انجام میدهد. ضرایب این مدل با استفاده از متغیرهای زیر حساب میشوند:
-- هزینه خواندن یک صفحه ۸ کیلوبایتی به صورت ترتیبی از دیسک
postgres=# SHOW seq_page_cost ;
seq_page_cost
---------------
1
(1 row)
-- هزینه خواندن یک صفحه ۸ کیلوبایتی به صورت تصادفی از دیسک
postgres=# SHOW random_page_cost ;
random_page_cost
------------------
4
(1 row)
-- هزینه بررسی یک سطر جدول
postgres=# SHOW cpu_tuple_cost ;
cpu_tuple_cost
----------------
0.01
-- هزینه بررسی یک ورودی ایندکس
postgres=# SHOW cpu_index_tuple_cost ;
cpu_index_tuple_cost
----------------------
0.005تخمین هزینه کل. با استفاده از مدل داخلی و این متغیرها، هزینه به ازای هر سطر تخمین زده میشود و ضرب در تخمین تعداد سطرها میشود و کل هزینه تخمین زده میشود.